
Your application is gaining traction-user registrations are booming, traffic is surging, and revenue is climbing steadily. But then, everything comes to a screeching halt. The system slows down under the pressure and eventually crashes. This is where software scalability becomes critical-it determines whether your system can gracefully handle growth or crumble under demand.
Scalability isn’t just about adding more servers. Without a clear strategy, performance bottlenecks are inevitable. Companies like Airbnb successfully scaled by moving from a monolithic structure to a microservices-based architecture. They embraced cloud hosting, implemented database sharding, and leveraged load balancing to manage increasing user demand efficiently.
Scalable software development takes into account both vertical scaling (enhancing server power) and horizontal scaling (distributing load across multiple servers). The architecture you choose today will dictate how well your app adapts tomorrow. Advanced tools like Apache Kafka Raw can streamline event streaming and handle large volumes of data traffic effectively.
Remember, scalability is not a one-time fix-it’s a continuous journey. Plan proactively, optimize regularly, and scale with precision to ensure your application remains robust as it grows.

What Is Software Scalability?
Software scalability refers to the ability of a system to manage increased demand efficiently-without performance loss. A scalable system ensures stability and responsiveness even as user numbers grow or traffic surges. It’s the backbone of sustainable digital success.
Types of Software Scalability
- Vertical Scaling: Enhancing performance by adding more CPU, memory, or storage to a single server.
- Horizontal Scaling: Increasing capacity by adding more servers to distribute the workload.
- Elastic Scaling: Automatically adjusting computing resources in real-time based on current demand.
Why Scaling Matters
Neglecting scalability can result in slowdowns, crashes, lost revenue, and frustrated users. Take Airbnb’s journey, for instance-initially built on a monolithic architecture, it eventually reached its limits under rapid growth. The switch to microservices enabled greater flexibility and scalability, proving that preparing for scale is crucial for long-term success.
Scalability Tools
Achieving seamless scalability requires the right set of tools to automate infrastructure management, monitor performance, and maintain system stability under high load. Companies rely on a mix of orchestration, monitoring, and cloud-native solutions to keep applications responsive and reliable as they grow.
- Kubernetes: A robust container orchestration platform that automatically scales applications and ensures consistent deployments across various environments.
- Docker Swarm: A simpler, lightweight alternative to Kubernetes for clustering and scaling containerized apps.
- AWS Auto Scaling: Dynamically adjusts AWS compute resources based on real-time traffic and usage to maintain performance and control costs.
- Elastic Load Balancing (ELB): Distributes incoming application traffic across multiple resources to boost availability and fault tolerance.
- Prometheus: A powerful open-source monitoring system that collects performance data and triggers alerts when issues arise.
- Grafana: Visualization tool that works with Prometheus and other data sources to create dashboards and monitor system metrics.
- Apache Kafka: A high-throughput, distributed event streaming platform used to build scalable data pipelines and connect services in real-time.
- Redis: An in-memory data structure store that improves speed by handling caching and message brokering to reduce database strain.
- Hystrix (by Netflix): A fault tolerance library that acts as a circuit breaker to prevent cascading failures in distributed systems.
- Terraform: An Infrastructure as Code (IaC) tool that automates cloud infrastructure provisioning and scaling across multiple platforms.
Airbnb: A Case Study in Software Scalability
Airbnb’s journey illustrates the challenges and rewards of scaling a fast-growing application. The company learned that premature scaling leads to over-engineering, while reactive scaling results in downtime and degraded user experience.
Premature scaling involves expanding infrastructure before the demand justifies it, leading to wasted resources and complexity.
Reactive scaling, on the other hand, means waiting until performance issues appear-often too late-resulting in bottlenecks and service interruptions.
Airbnb succeeded by proactively restructuring its architecture, embracing cloud-native technologies, and removing scalability constraints before they impacted performance.
Where Airbnb Faced Challenges:
- Monolithic Bottlenecks: Initially built on a monolithic Ruby on Rails application, Airbnb struggled with long deployment cycles and performance slowdowns as traffic grew.
- Database Constraints: A single, centralized database created performance issues, making it hard to handle increasing read/write operations efficiently.
- Engineering Inflexibility: The tightly coupled architecture hindered agility, where even minor updates required full deployments, slowing down innovation.
How Airbnb Achieved Scalability:
- Architecture Auditing: The team reviewed its legacy codebase to map out dependencies before moving to a microservices architecture.
- Service-Oriented Design: Breaking the monolith into smaller, independent services improved performance, fault isolation, and deployment speed.
- Adopting Kubernetes: Leveraging Kubernetes enabled dynamic scaling of services and better resource management.
- Database Sharding: Airbnb implemented sharded databases to distribute traffic and eliminate single points of failure.
- Traffic Management & Caching: Load balancing and caching strategies helped maintain performance and reliability during high-demand periods.
Scalability Strategies: What Works and What Doesn’t
Scaling isn’t just about adding more servers. True scalability means your system performs efficiently at any traffic level. Without the right strategy, even high-potential applications can stumble under load. Here's what effective scaling looks like-and what pitfalls to avoid.
1. Pinpoint and Resolve Bottlenecks
You can’t fix what you can’t see. Without detailed monitoring, you risk optimizing the wrong parts of your application. Tools like Prometheus and Grafana track system-level metrics (CPU, memory, disk I/O), while New Relic, Datadog, and AppDynamics provide insights into API latency and database performance.
Scalable architecture demands continuous visibility into performance. For example, Airbnb used EXPLAIN ANALYZE to uncover slow SQL queries like:
EXPLAIN ANALYZE
SELECT * FROM bookings WHERE user_id = 123;
If user_id isn’t indexed, the query causes a full table scan, increasing response time. Also, using SELECT * fetches unnecessary data, worsening performance. Poor data distribution or outdated stats can further misguide the query planner.
The fix:
CREATE INDEX idx_user_id ON bookings(user_id);
Indexing critical columns dramatically improves query speed and lowers database load. Airbnb also implemented sharding and replication to spread traffic across multiple databases, eliminating key bottlenecks.
Airbnb’s Workflow for Diagnosing Performance Issues:
- Monitor CPU, memory, and I/O in real-time
- Track API latency, throughput, and error rates
- Profile and optimize database queries
- Trace request paths across distributed services
During development, improving API responsiveness is essential. Airbnb adopted asynchronous processing to avoid having slow endpoints block the user experience. They also followed Site Reliability Engineering (SRE) practices to guide sustainable and scalable growth.
Common Pitfall: Many teams overlook background job queues and worker latency-until these hidden processes choke the system under high demand.
2. Optimize Before You Scale
Throwing more servers at a slow application won’t fix inefficient code-it just burns money faster. Before scaling infrastructure, it's essential to eliminate waste and bottlenecks in your codebase, queries, and asset delivery.
Optimize first, scale second. Caching with tools like Redis or Memcached can significantly ease database load:
cached_result = redis.get("user_123_profile")
if not cached_result:
data = db.query("SELECT * FROM users WHERE id = 123")
redis.set("user_123_profile", data)
As the saying goes: cache it or crash it.
Airbnb learned this the hard way when their monolithic system choked under traffic. Indexing and smarter query handling helped slash response times. They also offloaded static assets like images and scripts to Content Delivery Networks (CDNs), improving global load speeds by up to 40%.
These optimizations echo Martin Fowler’s philosophy: the foundation of scalability is clean, efficient code-not brute force hardware upgrades. Other major players like Slack and Shopify followed similar paths, tuning performance before scaling infrastructure.
Common Pitfall: Over-caching without proper expiration or invalidation logic can serve outdated data-creating bugs that are tougher to debug than a server outage.
3. Choose the Right Scaling Approach
There’s no universal solution to scaling-your strategy must match your growth stage and system architecture.
You generally have two options:
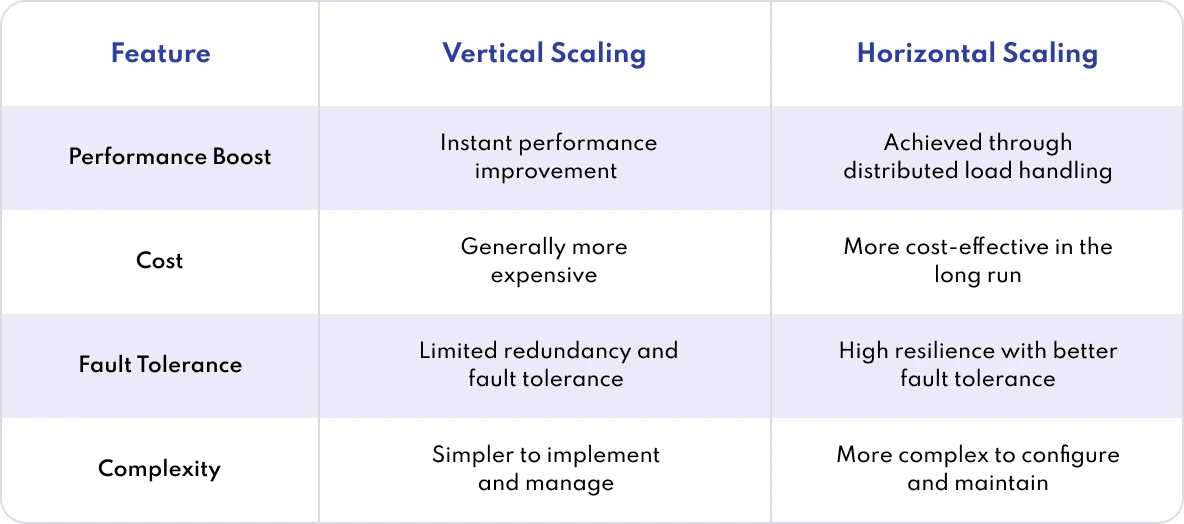
- Vertical Scaling: Add more resources (CPU, RAM) to a single machine. It’s simpler but hits a ceiling fast.
- Horizontal Scaling: Add more machines to distribute workloads. It’s complex but offers virtually limitless growth.
Airbnb began with vertical scaling, boosting server specs to meet demand. But they quickly ran into performance and cost limits. To truly scale, they pivoted to horizontal scaling, distributing workloads across multiple cloud nodes.
They leveraged Terraform, an Infrastructure as Code (IaC) tool, to automate provisioning and deployment-enabling repeatable, scalable infrastructure setup.
This shift wasn’t just technical-it was cultural. Airbnb embraced a new mindset:
“Horizontal all the things!”
Scaling Architecture: Building for Growth
The foundation of scalable software lies in its architecture. Choosing between a monolithic and microservices design can shape your system’s ability to handle growth, manage complexity, and maintain performance. Get it wrong, and you’ll find yourself tangled in a painful monolith-to-microservices migration.
1. Microservices vs. Monolith: When to Make the Move
Selecting the right architecture is one of the most critical decisions for long-term scalability. Monolithic systems are simpler to develop initially, but they become rigid and fragile as demands increase. Microservices provide flexibility and scalability but introduce operational complexity.
Airbnb’s journey is a textbook case: they started with a monolithic Ruby on Rails application. As their traffic soared, the architecture couldn’t keep up-causing slow deployments, massive database load, and system-wide risk from small changes.
Switching to a microservices architecture allowed Airbnb to isolate services, scale individual components, and deploy faster. But the shift was far from easy-they had to perform “architecture archaeology” to understand legacy dependencies before breaking things apart.
By contrast, Netflix took a proactive route-building with cloud-native principles from the beginning. They used Istio Service Mesh to manage service communication and Kubernetes to orchestrate workloads. This gave them a strong scalability advantage early on.
For many companies, the smartest path is to start with a monolith, modularize over time, and migrate to microservices when justified by growth and complexity.
2. Load Balancing: Keeping Traffic Flow Smooth
Distributing traffic effectively is key to maintaining software scalability. Without proper load balancing, even a well-architected system can buckle under pressure. Tools like AWS Elastic Load Balancer (ELB), Nginx, and HAProxy ensure requests are spread evenly across servers, preventing any one instance from becoming a bottleneck.
Essential Traffic Distribution Techniques:
- Elastic Load Balancing (ELB): Adapts dynamically to traffic spikes and dips, keeping your application responsive.
- Rate Limiting & Throttling: Controls request volume, protecting systems from abuse and unintentional overload.
- Global Load Balancing: Routes users to the geographically closest server, reducing latency and improving user experience.
Load balancing not only improves availability but also helps scale applications efficiently by optimizing how resources are utilized across your infrastructure.
3. Database Scaling Strategies: Learning the Hard Way
Scaling the application layer is only half the battle-your database must scale with it. Airbnb learned this the hard way. Their first attempt at database sharding created more problems than it solved due to poor shard key selection and uneven data distribution.
To relieve pressure on their primary database, Airbnb introduced a Write Master / Read Replica architecture. Writes were funneled to a single authoritative database, while Read Replicas handled the high volume of read operations. But replication lag and uneven load distribution exposed the risks of scaling without a strategy.
Eventually, Airbnb refined their approach:
- Chose more effective shard keys to balance workloads
- Implemented automated shard management tools
- Enhanced query routing to reduce latency
- Monitored replica sync health to avoid data inconsistencies
To support real-time operations, Airbnb also adopted an event-driven architecture using Apache Kafka, improving data flow between services and ensuring their system could scale under heavy load.
Their key takeaway? You can’t debug scalability in production-build it in from the start.
Scalability Testing: Preparing for Real-World Growth
If you’re not testing for scalability before your user base explodes, you're setting yourself up for failure. Adding more servers or simulating traffic is not enough. True scalability testing ensures your system can handle heavy load and unexpected breakdowns. Without it, even robust-looking systems can crumble when demand surges.

1. Load Testing Before It's Too Late
Airbnb’s early scaling issues were a wake-up call-they discovered that scaling without testing first is a recipe for outages. When demand spiked, their infrastructure faltered, leading to downtime and rushed fixes.
The lesson? Simulate real-world usage before it happens.
Tools like JMeter, Locust, and k6 allow teams to model actual user behavior under load. For example, you can run:
k6 run --vus 1000 --duration 1m script.jsThis simulates 1,000 virtual users for one minute, revealing bottlenecks and failure points in your API.
Eventually, Airbnb adopted a more proactive strategy. Inspired by Netflix, they implemented scalable backend practices with load generators, rate limiting, and internal chaos engineering tools to push their system under stress and failure conditions-not just ideal ones.
They integrated these performance tests into their CI/CD pipeline, ensuring every deployment was load-tested before release. Metrics like throughput, latency, and error rate were continuously monitored to fine-tune performance and avoid regression.
Pro tip: Don't just test for consistent high traffic-test for sudden spikes, maximum concurrency, and how your database behaves when resources are strained.
Auto-Scaling and Self-Healing Systems: Scaling Smarter, Not Harder
Elasticity isn’t just a luxury-it’s a necessity for modern scalable software. Manual scaling wastes engineering time and inflates cloud bills. Instead, companies like Airbnb adopted container orchestration with Kubernetes, leveraging Horizontal Pod Autoscaler (HPA) to dynamically scale workloads based on real-time demand.
Here’s a sample HPA configuration:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: web-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-service
minReplicas: 2
maxReplicas: 10
targetCPUUtilizationPercentage: 75
This setup allows systems to automatically scale between 2 and 10 replicas depending on CPU usage, giving Airbnb the ability to right-size resource usage, optimize performance, and manage cloud costs without manual intervention.
But auto-scaling is only half the battle. Self-healing capabilities are just as critical for resilience. Airbnb adopted circuit breaker patterns, inspired by Netflix’s Hystrix, to gracefully isolate failing services and prevent cascading outages. This meant services could recover or reroute automatically without bringing the entire system down.
To ensure these mechanisms were actually working, Airbnb implemented deep observability. With tools like Prometheus and Grafana, they monitored Service Level Objectives (SLOs), catching performance anomalies early-before users were affected.
Key takeaway: Auto-scaling helps you grow efficiently. Self-healing helps you survive. But without real-time observability, both systems can silently fail-and you won’t know until it’s too late.
Common Scalability Mistakes
You roll out a new feature. Everything seems fine at first. Then traffic surges. Requests stack up, response times lag, and error messages start showing up everywhere. Customers get frustrated and bounce. You try throwing more servers at the problem, but the slowdown isn’t about hardware. It’s your architecture.
Good software development creates systems that minimize risks, avoid single points of failure, and perform reliably. Poor software architecture leads to scalability challenges that cripple growth.
Premature Optimization
The best is the enemy of good enough. Building for millions of users before you have 50, wastes time and money.
Airbnb didn’t start with high software scalability in mind. They chose early speed and simplicity with their monolithic Ruby on Rails app. Later, instead of jumping straight to complex scaling patterns, they focused first on improving operational efficiency. They optimized their application programming interface (API), cleaned up processing logic, and tuned their internal software for real-world use.
Their scaling strategy was measured and deliberate. They used traffic distribution software and moved toward horizontal software scalability. They broke out services only where they needed to. They simplified their cloud computing services and postponed unnecessary workload distribution. Netflix took a similar software engineering path, applying CAP Theorem tradeoffs to balance data consistency with performance at scale.
The lesson? Don’t over-engineer. Prep to scale but remember, you don’t need a global load balancer before you’ve got global users.
Ignoring Observability
Unseen latency issues can quietly erode performance over time. Without monitoring, issues stay hidden until they cripple performance. Enterprise software must track network latency, incoming requests, and data consistency to maintain stability.
Airbnb initially lacked a telemetry monitoring system. That led to slow debugging and undetected single points of failure. Their early mistakes show why observability is critical for better software scalability.
How Airbnb Improved Observability:
- Adopted Prometheus & Grafana: Added real-time tracking of software scaling issues.
- Implemented log aggregation frameworks: Provided centralized visibility into average response time throughput.
- Monitored cloud performance: Reduced network latency and improved response to incoming requests.
Scaling Software by Adding Hardware Alone
Sudden traffic surges stress every part of your stack.
A fast-growing startup rolls out a marketing campaign that brings in a flood of new users overnight. To keep up, the engineering team upgrades to bigger servers and more powerful instances. It works at first, but soon the performance issues come back. Response times lag, error rates spike, and cloud costs skyrocket. Turns out, the real issue wasn’t a lack of power. It was inefficient code, a database struggling to keep up, and a single-threaded architecture that couldn’t keep up with demand.
Cloud computing gives you rapid scaling, but poorly optimized software systems still buckle under pressure.
Airbnb started with vertical scaling. They added power to their existing server infrastructure rather than addressing architectural inefficiencies. That increased their GPU error rate cost and caused poor data integrity.
Conclusion
Building scalable software requires more than just adding resources-it demands thoughtful architecture, continuous monitoring, and careful optimization. Avoiding common pitfalls like premature optimization, ignoring observability, and relying solely on hardware upgrades can save time, reduce costs, and improve user experience. Learning from companies like Airbnb, it’s clear that a deliberate, data-driven approach combined with the right tools and strategies lays the foundation for scalable, resilient, and high-performing applications ready to grow with demand.
Ready to scale your software with confidence?
Partner with Techlattice to build resilient, high-performance systems that grow seamlessly with your business and keep your users happy.
